
Deep Learning vs. Machine Learning: ¿cuáles son las diferencias?

Deep Learning vs. Machine Learning: ¿cuáles son las diferencias?
La inteligencia artificial (IA) es una potente herramienta de comunicación tecnológica. Deep Learning y Machine Learning son elementos indispensables para repensar cómo integramos la información, analizamos los datos y utilizamos los conocimientos resultantes. Todo lo anterior con el fin de mejorar procesos de nuestra vida cotidiana.
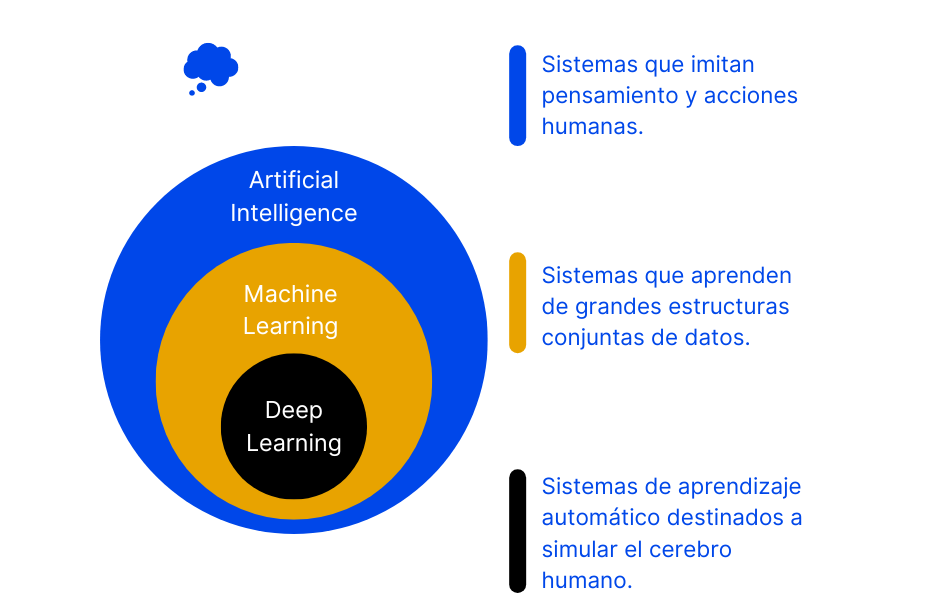
La IA es una rama del estudio y la investigación informática que busca formas de imitar el funcionamiento de las neuronas humanas en las máquinas. También pretende resolver problemas basados en el comportamiento humano, mediante mecanismos matemáticos y lógicos.
En este post del blog de Agencia Vilo queremos invitarte a recorrer el artículo que publicó originalmente en inglés Michael Middleton en el blog de Flatiron School, una prestigiosa escuela tecnológica de Nueva York.
«Para comprender en profundidad los conceptos de inteligencia artificial, deep learning y machine learning se necesitan tener las siguientes ideas claves» – Middleton:
- El aprendizaje profundo (Deep learning) es un tipo de aprendizaje automático y es un subconjunto de la Inteligencia Artificial (IA).
- Mientras que el deep learning se relaciona con estructuras modeladas inspiradas en la funcionalidad del cerebro humano para que las máquinas aprendan a “pensar”, el machine learning se produce cuando los ordenadores pueden pensar y actuar con poca intervención humana.
- El machine learning requiere menos poder de computación; el deep learning generalmente necesita menos intervención continua del ser humano.
- El deep learning puede analizar imágenes, videos y datos no estructurados, funciones que el machine learning no puede realizar fácilmente.
- En el futuro cada sector económico deberá emplear profesionales capaces de involucrar máquinas y deep learning en sus procesos.
¿Qué es la inteligencia artificial (IA)?
El autor del artículo Michael Middleton afirma que la Inteligencia Artificial (IA) es una ciencia dedicada a estudiar la forma en que las máquinas puedan pensar y actuar como los seres humanos.
El significado puede parecer simplista, pero ningún ordenador comprende inicialmente la complejidad de la inteligencia humana. Las computadoras destacan en la aplicación de reglas y la ejecución de tareas. Pero en ocasiones una tarea relativamente sencilla para una persona puede ser muy compleja para una máquina.
Tal como llevar una bandeja de bebidas a través de un bar lleno de gente y servirlas al cliente correcto es algo que los camareros hacen todos los días. Es un ejercicio complejo de toma de decisiones y se basa en un gran volumen de datos que se transmiten entre las neuronas del cerebro humano.
Los ordenadores aún no alcanzan ese nivel, pero el deep learning y el machine learning son pasos hacia un elemento clave de este objetivo: analizar grandes volúmenes de datos y tomar decisiones/predicciones basadas en la información adquirida con la menor intervención humana posible.
¿Qué es el machine learning?
Machine learning es para Michael Middleton un subapartado de la inteligencia artificial que se enfoca en un objetivo específico: configurar los ordenadores para que puedan realizar tareas sin la necesidad de una programación explícita.
Los computadores se alimentan de datos estructurados (en la mayoría de los casos) y «aprenden» a ser mejores en la evaluación y acción sobre esos datos a lo largo del tiempo.
Piensa en los «datos estructurados» como entradas de datos que puedes colocar en columnas y filas. Y es posible crear una columna de categoría en Excel llamada ‘comida’ y tener entradas de fila como ‘fruta’ o ‘carne’. Esta forma de datos ‘estructurados’ es muy fácil de usar para los ordenadores, y los beneficios son múltiples.
Una vez programado, un ordenador puede tomar nuevos datos indefinidamente, clasificándolos y actuando sobre ellos sin necesidad de mayor intervención humana.
Con el tiempo, el computador puede reconocer que la ‘fruta’ es un tipo de alimento, incluso si deja de etiquetar sus datos. Esta «autosuficiencia» es tan fundamental para el machine learning que el campo se divide en subconjuntos en función de la cantidad de ayuda humana involucrada.
El aprendizaje supervisado y el aprendizaje semi supervisado
El aprendizaje supervisado es una subcategoría dentro del machine learning. Con este tipo de tecnología la máquina requiere la participación humana de forma más continua, de ahí el nombre «supervisado». El ordenador recibe datos de entrenamiento y un modelo diseñado explícitamente para «enseñarle» cómo responder a esa información.
Una vez que el modelo está preparado, se pueden ingresar más datos en el ordenador para ver qué tan bien responde. Y el programador o el data scientist (científico de datos) puede confirmar predicciones precisas o emitir correcciones para cualquier respuesta incorrecta.
Imagina a un programador tratando de enseñarle a un ordenador la clasificación de imágenes una a una. Primero introduce las imágenes para después pedirle a la máquina que las clasifique. Para que después, termine supervisando, confirmando o corrigiendo, cada acción que realice.
A lo largo del tiempo, este nivel de supervisión ayuda a perfeccionar el modelo hasta convertirlo en una tecnología con capacidad para manejar con precisión nuevos conjuntos de datos. Que estos, a su vez, serán capaces de seguir los patrones aprendidos. Este modelo pretende evitar la monitorización continua, porque no sería eficiente revisar constantemente el trabajo del ordenador y tener que realizar nuevos ajustes.
En este orden de ideas, en el aprendizaje semi supervisado, el ordenador recibe una combinación de datos correctamente etiquetados y datos no etiquetados, y busca patrones por sí mismo. Los datos etiquetados sirven como «guía» para el data scientist, pero no emiten correcciones constantemente.
El aprendizaje sin supervisión
El aprendizaje no supervisado lleva a la IA un paso más allá mediante el uso de datos no etiquetados. El ordenador tiene la libertad de encontrar patrones y asociaciones como mejor le parezca. A menudo generando resultados que podrían no haber sido evidentes para un analista de datos (humano).
El profesional que se dedica al análisis de datos es la persona que recupera y recopila información y la organiza para llegar a conclusiones significativas, y lo realiza así en todos los sectores.
Retomando el tema, un uso común para el aprendizaje no supervisado es la «agrupación». Donde el ordenador organiza los datos en temas comunes (como categorías) y capas que identifica. Los sitios web de compras o comercio electrónico utilizan habitualmente esta tecnología para decidir qué recomendaciones hacer a usuarios específicos en función de sus compras anteriores.
El aprendizaje por refuerzo
En el aprendizaje supervisado y en el aprendizaje no supervisado, no existen ‘consecuencias’ para el ordenador si no comprende o categoriza correctamente los datos.
Pero, ¿qué pasaría si, como un niño en la escuela, la máquina recibiera feedback positivo cuando hace lo correcto y feedback negativo cuando realiza lo incorrecto?
Presumiblemente, el ordenador comenzaría a descubrir cómo realizar tareas específicas mediante ensayo y error. Sabiendo que se encuentra en el camino correcto cuando recibe una recompensa (por ejemplo, una puntuación) que refuerza su ‘buen comportamiento’.
Este tipo de aprendizaje por refuerzo es fundamental para ayudar a las máquinas a dominar tareas complejas que se nutren de conjuntos de datos grandes, altamente flexibles e impredecibles.
El desarrollo de esta tecnología abre la puerta a los ordenadores que intentan lograr un objetivo. Como por ejemplo realizar una cirugía, conducir un automóvil, escanear el equipaje en busca de objetos peligrosos, etc.
¿Qué ventajas ofrece la tecnología de machine learning hoy en día?
Puede que te sorprenda saber que interactúas con herramientas machine learning todos los días. Por ejemplo, Google la utiliza para filtrar el spam, el malware y los intentos de phishing en tu bandeja de entrada.
Tu banco y tu tarjeta de crédito lo emplea para generar avisos sobre transacciones sospechosas en tus cuentas. Cuando hablas con Siri y Alexa, el machine learning impulsa las plataformas de reconocimiento de voz y del habla en el trabajo. O cuando tu médico te envía a un especialista, el machine learning puede ayudarle a analizar las radiografías y los resultados de los análisis de sangre en busca de anomalías como el cáncer.
A medida que las aplicaciones siguen creciendo, se recurre al machine learning para manejar tipos de datos cada vez más complejos. Hay una fuerte demanda de ordenadores que sean capaces de manejar datos no estructurados, como imágenes o vídeos. Y aquí es donde entra en escena el machine learning.
Descubre cómo ayudamos a Qualud a superar los retos de comunicación de la organización
¿Qué es el deep learning?
El machine learning consiste en que los ordenadores sean capaces de realizar tareas sin ser programados explícitamente, pero los ordenadores siguen pensando y actuando como máquinas.
Su capacidad para realizar algunas tareas complejas -recopilar datos de una imagen o un vídeo, por ejemplo- sigue estando muy lejos de lo que son capaces los humanos.
Los modelos de deep learning introducen un enfoque extremadamente sofisticado para el machine learning y están listos para afrontar nuevos retos. Porque han sido modelados e inspirados específicamente a partir de la estructura del cerebro humano. Las «redes neuronales profundas», complejas y de múltiples capas, se construyen para permitir que los datos pasen entre los nodos (como las neuronas) de forma altamente conectada. El resultado es una transformación no lineal de los datos que es cada vez más abstracta.
Si bien se necesitan enormes volúmenes de datos para «alimentar y construir» un sistema de este tipo. Estas redes pueden comenzar a generar resultados inmediatos, existiendo una necesidad relativamente pequeña de intervención humana, una vez que los programas están implementados.
Tipos de algoritmos de Deep Learning
Michael Middleton agrega en su artículo que cada vez son más los algoritmos de deep learning disponibles para alcanzar nuevos retos y objetivos dentro del extenso campo de la inteligencia artificial.
Dos de estos grandes objetivos, en los que los data scientists e ingenieros de datos aplican deep learning, son las redes:
- Neuronales convolucionales.
- Neuronales recurrentes.
Las redes neuronales convolucionales
Éstas son algoritmos especialmente construidos y diseñados para trabajar con imágenes.
La ‘convolución’ se refiere al proceso que aplica un filtro basado en el peso de cada elemento de una imagen, lo que ayuda al ordenador a comprender y reaccionar a los elementos dentro de la imagen misma.
Esto puede ser útil cuando se necesita escanear un gran volumen de imágenes para un elemento o característica específica. Un clave ejemplo son las imágenes del fondo del océano para encontrar señales de un naufragio, o la foto de una multitud para hallar el rostro de una sola persona.
Esta ciencia del análisis y la comprensión de imágenes/vídeos informáticos se denomina «visión artificial» y representa un área de gran crecimiento en la industria de los últimos diez años.
Redes neuronales recurrentes
Mientras tanto, las redes neuronales recurrentes introducen un elemento clave en el machine learning que está ausente en los algoritmos más sencillos: la memoria.
El ordenador es capaz de recordar decisiones y redes de datos del pasado para considerarlos cuando se revise información (más datos) del presente. En el proceso también se tiene en cuenta, además, el gran poder que tiene la información contextual.
Estas características han convertido a las redes neuronales recurrentes en un foco importante para el trabajo de procesamiento del lenguaje natural. Al igual que le ocurre a un ser humano, el ordenador realizará un mejor trabajo al comprender una sección de texto si tiene acceso al tono y al contenido que le precedía.
A modo de ejemplo, las direcciones de conducción pueden ser más precisas si el ordenador ‘recuerda’ que todos los que siguen una ruta recomendada un sábado por la noche tardan el doble en llegar a su destino.
5 diferencias claves entre el Machine Learning y el Deep Learning
Si bien hay muchas diferencias entre estas dos ramificaciones de la inteligencia artificial, Michael Middleton destaca cinco:
1. La intervención humana
Hay que resaltar, por un lado, que el machine learning requiere una intervención humana continuada para obtener resultados. Por otro lado, el deep learning es más complejo de configurar, pero requiere una intervención humana posterior mínima.
2. Hardware
Los programas de machine learning tienden a ser menos complejos que los algoritmos de deep learning y, a menudo, pueden ejecutarse en computadoras convencionales. Mientras que los sistemas de deep learning requieren hardware y recursos mucho más potentes.
Aquel aumento de la demanda de energía ha impulsado y ha significado un mayor uso de unidades de procesamiento gráfico. Las CPU son útiles por su gran ancho de banda y su capacidad para ocultar la latencia (retrasos) en la transferencia de memoria debido al paralelismo de subprocesos. Este último, es la capacidad de muchas operaciones para ejecutarse de manera eficiente al mismo tiempo.
3. Tiempo
Los sistemas de machine learning se pueden configurar y son capaces de operar rápidamente, pero pueden mostrar resultados limitados.
Por el contrario, los sistemas de deep learning tardan más en configurarse, pero pueden generar resultados instantáneamente (aunque es probable que la calidad mejore con el tiempo a medida que haya más datos disponibles -y la máquina los haya aprendido-).
4. Enfoque
En este sentido, el machine learning tiende a requerir datos estructurados y utiliza algoritmos tradicionales como la regresión lineal. Mientras que el deep learning emplea redes neuronales y está diseñado para adaptarse a grandes volúmenes de datos no estructurados.
5. Aplicaciones
Por último, el machine learning ya está en uso en la bandeja de entrada de tu correo electrónico, en la relación con tu banco y con tu consultorio médico. La tecnología de machine learning permite programas más complejos y autónomos, como coches automáticos o robots que realizan cirugías avanzadas.
El futuro del machine learning y el deep learning
En conclusión, el deep learning y el machine learning impactarán nuestras vidas en las generaciones venideras y prácticamente todos los sectores se transformarán por sus capacidades. Trabajos más peligrosos como los viajes espaciales o actividades en entornos hostiles podrían reemplazarse por completo con la participación de las máquinas.
Al mismo tiempo, la gente recurrirá a la inteligencia artificial para ofrecer nuevas y ricas experiencias de entretenimiento que hoy todavía parecen material de ciencia ficción.
Si deseas aprender sobre machine learning, deep learning o necesitas ayuda para impulsar la comunicación de tu organización, no dudes en contactar con Agencia Vilo.
Puedes consultar sin compromiso el listado de servicios de la agencia o incluso suscribirte a nuestra newsletter clicando en el botón amarillo que encontrarás al final de esta página.
Recuerda, también, que te invitamos a seguir toda nuestra actualidad a través de nuestras redes sociales, en Instagram, Facebook y LinkedIn.
Compartir
Suscríbete a nuestra newsletter
Te recomendamos
Categorías
Entradas recientes
- Escrito por Daniel H. Devia Beltran




